
阿里巴巴集团联合创始人、董事长蔡崇信在香港大学陆佑堂做了一次演讲。这是港大商学院”陈坤耀杰出讲座系列”的年度活动。据说,17年前,马云曾站在同一个舞台上。主办方说,这次演讲的报名速度创下纪录:邮件发出两小时内,超过1200人报名。
一、中国AI的真正优势:不是模型,是整个生态
蔡崇信开场就抛出一个反直觉的观点:美国人定义的AI竞赛规则是错的。
美国人怎么算谁赢?看谁的大语言模型(Large Language Model)更强。今天是OpenAI领先,明天是Anthropic,后天可能是别人。但蔡崇信说,这个计分方式本身就有问题。
真正的赢家不是谁有最好的模型,而是谁用得最好。
“The winner is not about who has the best model. The winner is about who could use it the best in their own industries, in their own lives.” (赢家不是看谁模型最好,而是看谁在自己的行业和生活中用得最好。)
这个判断的底层逻辑是:AI的价值在于渗透率(penetration rate)。中国国务院的AI规划就很务实——到2030年,AI代理和设备的渗透率要达到90%。不讲玄学,只讲普及。
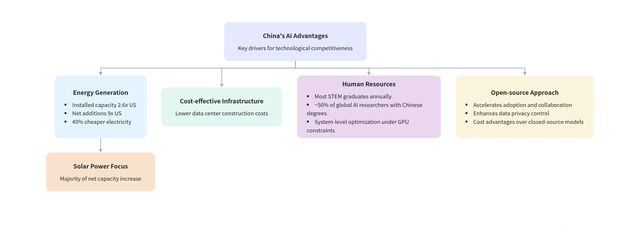
那中国凭什么能普及得更快?蔡崇信列了一张完整的底牌清单。
1、电力:15年前埋下的伏笔
训练大模型、跑推理(inference),本质上都是在烧电。中国的电力成本比美国低40%。
为什么?因为15年前中国就开始大规模投资电力传输基础设施。北方发的电要送到南方,新能源产地和用电需求地往往不重合,必须靠输电网络打通。中国国家电网每年资本支出900亿美元,美国只有300亿——三倍的差距。
结果是什么?中国的电力装机容量是美国的2.6倍,而且新增装机容量是美国的9倍。这个差距还在拉大。
2、数据中心:成本碾压
在中国建一个数据中心,成本比美国低60%。这还没算芯片,只是基建。
3、工程师红利:全球一半的AI人才有中国学历背景
蔡崇信提到一个有趣的数据:全球几乎一半的AI科学家和研究人员,都有中国大学的学位——无论他们现在在美国公司、中国公司,还是世界任何地方工作。
他还讲了个段子。最近社交媒体上有人吐槽,说自己在Meta(Facebook)的AI团队里,同事们都在用中文交流想法,他完全听不懂。
“This is the first time Chinese language is an advantage.” (这是中文第一次成为一种优势。)
以前中国公司出海,语言是劣势——在意大利开办公室,当地人不会说中文,中国员工得用第二语言沟通。但在AI领域,全球的华人工程师用中文分享想法、交换思路,这反而成了信息优势。
4、资源匮乏逼出来的系统级创新
美国有大量GPU,中国没有。但蔡崇信说,匮乏反而创造了优势。
“China being lacking in GPUs actually creates an advantage of starvation. When you don’t have a lot of resources, you are forced to innovate at the systems level.” (GPU的缺乏反而创造了’饥饿优势’。当你没有足够资源时,你被迫在系统层面创新。)
训练一个万亿参数的模型,如果系统效率不高,GPU消耗会非常恐怖。中国团队因为硬件受限,必须把系统优化做到极致。DeepSeek就是这么逼出来的——阿里的通义千问(Qwen)模型刚刚赢得了一场为期两周的加密货币和股票交易AI竞赛,DeepSeek排名第二。
蔡崇信对DeepSeek毫不吝惜赞美:”我们在杭州的邻居,他们做的事情令人难以置信。”
二、开源为什么会赢:成本、主权、隐私的三重逻辑
这可能是整场演讲最核心的判断。
蔡崇信的观点很直接:开源模型会击败闭源模型,不是因为开源更先进,而是因为开源更符合全球大多数用户的利益。
他举了个例子。假设你是沙特阿拉伯,想发展AI,又想保持”AI主权”(sovereign AI)——意思是AI不受外国控制。但你没有人才自己开发模型。
这时候你有两个选择:
选择一:通过API使用OpenAI。付很多钱,而且数据要喂进去——你不知道数据去了哪里,那是个黑箱(black box)。
选择二:直接下载阿里的开源模型,部署在自己的私有云上。免费,而且数据完全可控。
成本和隐私,两边都赢。所以无论是政府还是企业,只要认真做成本效益分析,都会倾向于开源。
那阿里怎么赚钱?
蔡崇信说得很坦白:”我们不靠AI赚钱。”
阿里靠的是云计算。你用开源模型没问题,但你要跑模型,需要云基础设施——存储、数据管理、安全、网络、容器(containers,他说这个词他自己也不太懂)。这些阿里都能提供。开源模型是流量入口,云服务才是利润来源。
这个模式其实很像早年的互联网公司:免费产品获客,增值服务变现。只不过规模和技术门槛完全不同。
三、阿里巴巴的进化逻辑:永远跟着客户需求走
港大教授邓希炜问了一个好问题:阿里从B2B电商变成AI云计算公司,秘诀是什么?
蔡崇信的答案很朴素:没有秘诀,就是跟着客户需求走。
阿里1999年成立时,中国还没加入WTO,国际贸易必须通过国有贸易公司。2001年入世之后,小企业可以直接和全球做生意了。阿里的B2B平台就是帮这些小厂找买家——第一版网站是英文的,面向海外。
后来消费者电商起来了,就有了淘宝。买家和卖家互不信任,就发明了支付宝(最初是个担保交易系统)。物流跟不上,就投资物流。
云计算也是一样的逻辑。16年前,没人讨论云。但阿里的消费平台要处理海量数据,如果继续用Dell的服务器、EMC的存储、Oracle的数据库,所有利润都会交给这些供应商。
阿里的CTO说:我们得自己搞。
“We developed cloud computing really out of necessity, out of the need to become self-reliant in technology.” (我们发展云计算完全是出于必要,出于对技术自主可控的需求。)
所以阿里云的起点是”自己吃自己的狗粮”(eat our own dog food)——先内部用,用好了再开放给外部客户。
蔡崇信对年轻创业者的建议也很明确:优先选择有机增长(organic development),而不是并购。因为自己团队培养出来的能力,DNA纯正,文化匹配。阿里也做过并购,”有些成功,有些失败得很惨”。
四、给年轻人的建议:学会提问,比学会回答更重要
演讲最后有学生问答环节。蔡崇信关于技能和专业选择的回答,信息密度很高。
1、技能层面:三件事
第一,学会获取知识。 听起来是废话,但在AI时代,知识获取的效率差异会被放大。
第二,建立分析框架。 不是死记硬背,而是能对信息做出自己的判断。
第三,学会提问。 蔡崇信特别强调这一点——提出正确的问题(ask the right questions),比找到答案更重要。
2、要不要学编程?要,但理由变了
很多人说AI时代不用学编程了,用自然语言(natural language)就能指挥机器。蔡崇信不同意。
他说学编程的目的不是为了操作机器,而是训练思维过程。
“The purpose is not to actually operate a machine. The purpose is going through that thinking process.” (目的不是操作机器,而是经历那个思考过程。)
他甚至建议学电子表格——能把一个复杂公式写对,让数字自动计算出来,这本身就是逻辑训练。
3、专业选择:三个方向
数据科学(data science):其实就是统计学的新名字,但未来数据会爆炸式增长,懂得管理和分析数据的人永远稀缺。
心理学和生物学:理解人脑怎么运作。人脑仍然是最高能效的”机器”,AI的很多设计思路都来自对大脑的模拟。
材料科学(material science):世界现在被比特(bits)主导,但让比特跑得更快的,是原子(atoms)。半导体领域会有大量创新,而半导体的核心就是材料。
五、一个关于风险的故事:为什么加入创业公司
1999年,蔡崇信放弃香港的律师高薪,跑去杭州加入一个18人的小公司。为什么?
他的回答是金融人的思维:不对称风险收益(asymmetric risk-reward)。
“The downside risk was very limited. Why? Because I have a good university degree. I went to law school. Worst comes to worst, I can always work as a lawyer. The upside is unlimited.” (下行风险非常有限。为什么?因为我有好的学历,读过法学院,最坏情况我还能当律师。但上行空间是无限的。)
这就像一个看涨期权(call option)——最多亏掉权利金,但收益没有上限。
但他补充了一句更重要的话:机会是来找你的,不是你去找它的。 你要做的是”准备好”(preparedness),这样机会来的时候才能抓住。
六、AI会是泡沫吗?两个概念要分清
学生问:AI会不会像2000年互联网泡沫一样破裂?
蔡崇信说,要区分两种泡沫:
金融市场泡沫(financial market bubble):股票估值是不是太高?50倍市盈率合不合理?”这是一门艺术,我不知道。”
技术泡沫(real bubble):技术本身是不是虚假的?
他的判断是:AI可能存在金融泡沫,但技术本身是真实的。 就像2000年3月互联网泡沫破裂,但互联网并没有消失——今天互联网比那时候强大得多。
所有投入AI基础设施的资源、模型开发的努力,不会打水漂。
七、关于体育投资:一个关于文化交流的彩蛋
蔡崇信拥有NBA布鲁克林篮网队。今年篮网时隔六年重返中国(澳门),这是他主动推动的。
但他做体育投资最有意思的部分,是一个教育项目:每年选6-8个中国初中生,送去美国读高中、打篮球。
“The biggest beneficiaries are the high school kids in the US. They see these kids coming from China. They’ve read about China but they haven’t interacted with individuals.” (最大的受益者是美国的高中生。他们看到这些中国孩子来了,他们读过关于中国的东西,但从没和个体互动过。)
他说这是在”复制自己的经历”——13岁离开台湾去美国读书。人与人的交流(people-to-people exchange),比任何官方渠道都重要。
三个最核心的洞察
Q1:中国AI的真正优势是什么?
不是模型本身,而是让AI被广泛使用的整个生态系统。电力成本低40%、数据中心建设成本低60%、全球一半AI人才有中国学历、资源匮乏逼出系统级创新——这些加在一起,让中国更有可能实现AI的大规模普及。而普及率才是真正的计分板。
Q2:为什么开源模式会赢?
因为对全球大多数用户来说,开源同时解决了成本、数据主权和隐私三个问题。闭源模型要付费,数据要喂进黑箱;开源模型免费,数据可以留在本地。这不是技术优劣之争,是利益格局使然。
Q3:年轻人应该怎么为AI时代做准备?
学编程不是为了写代码,而是训练逻辑思维;学统计(数据科学)是因为数据会爆炸;学心理学是因为要理解人脑这个最高效的”机器”;学材料科学是因为让比特跑得更快的是原子。更重要的是,学会提出正确的问题——这比找到答案更有价值。
以下为翻译原文
阿里最早做的是一个B2B跨境贸易网站,1999年上线时是全英文的,主要为了帮助中国中小企业“走出去”。
后来,随着国内市场崛起、消费者行为转变,他们顺势延伸到C端,从阿里巴巴到淘宝,从企业到个人,业务自然生长。

随后支付宝的诞生,也是为了解决买卖双方的信任危机:买家不敢先付钱,卖家不敢先发货。阿里则提出一个托管机制,先由第三方保管资金,再根据交易结果释放。
这个简单的机制,为当时互联网的商业体系补上了一环:信任基础设施。
- “If you want to found companies later on, you would always want to favor organic development over acquisitions. […] because you are developing through your team, and your team has the best DNA in terms of the Alibaba culture and innovation.”
“好的公司不是靠收购堆出来的,而是有机长出来的。”
阿里进入云计算,实则是被利润结构倒逼的技术自救。那时,阿里的电商系统已经处理海量数据。每笔交易背后都有几十个数据库调用、支付、搜索、推荐。而服务器来自戴尔、存储来自EMC、数据库靠Oracle。
当时,阿里的CTO警告:
- “If we continue to use third-party software and hardware, we will later on hand over all our profits to these technology vendors.”
也就是说,如果延续这种依赖第三方服务的方式,上游一加价,利润全蒸发。所以,他们决定做自己的云。这不是简单的“租服务器”,而是做一个“跨数据中心的分布式操作系统”,支撑亿级用户的并行计算。阿里云最早的客户,就是阿里自己,也就是所谓的dogfooding(软件公司自己用自己的产品),再推向外部。
这套逻辑,十几年后被国家战略验证。
“技术自主可控”如今已是政策共识。
阿里当年的选择,或许在某种意义上,也是中国数字基础设施自主化的缩影。
- “China wants to continue to be a manufaturing powrehouse, I think the empasis on the manufacturing economy, which is part of the real economy is right there.”
十五五规划的第一个关键词,就是制造业强国。中国的消费占GDP比重不到40%,而美国是70%。这说明中国的经济仍然以生产和出口为核心。“中国在未来的十到二十年内,仍会是全球制造中心。”制造业带来就业、工资、出口和技术外溢,是最稳定的、最具复利效应的增长引擎。
回顾中国经济崛起的路径,从人均800美元提升到1.3万美元(并有望在未来十年达到3万美元),真正推动这一跃升力量的,就是生产制造以及全球供应体系。
- “They say, China is exporting excessive capacity for the rest of the world. […] The definition simply means that you have producation capacity that your domestic economy cannot absorb, therefore you resort to exports.”
“过剩产能只是国内消化不了的产能。[…] 通过出口,把产能转化为价值,本身就是国家致富的合理路径。”德国长期依靠汽车出口支撑经济,却从未被指责为‘产能过剩’。那么,中国制造业的外向型增长也不应被污名化,而应被视为一种经济体的自然演化。成为“世界制造中心”,是中国选择的正确路径,但这条路需要不断升级。过去我们出口的是鞋子和衣服,未来出口的将是电动车、电池和光伏。这三样,正好对应全球能源转型的刚性需求。制造业的升级,直接牵引了AI的落地方向。因为AI真正的规模效应,就体现在工业环节的降本增效上。

十五五规划的第二个关键词,尤其在当前地缘政治的背景下,是技术自主。
- “We want to become technology self reliant. […] The AI plan simply said that in 2030, we should see 90% penetration of AI agents and devices.”
到2030年,AI代理与设备要达到90%渗透,落地机制是市场化。这是一个应用导向的目标。
与之相比,美国的AI政策关注技术前沿,例如模型参数、算法突破;而中国的政策,更像是一场普惠运动,要让AI变成电力一样,成为基础设施,被更广泛使用。
- “You don’t keep score by looking at you know how good these large language models are; the score is being kept by the adoption rate”
这种差异是结构性的。
中美AI竞赛的关键不在技术指标,而在adoption rate(采用率)。AI的社会红利,并不来自一两个SOTA模型,而在于全社会的普及曲线。当农民、制造业工人、教师、小商户等等各行各业都能用AI时,这项技术才真正进入经济血液。
因此,中国的AI发展策略,本质上是“普惠型AI”:
- 技术领先不等于社会收益的最大化,普及速度才是复利起点。
- 允许国企和民企各自探索路线。政府不指定技术方向,只设定渗透目标;
- 把采用率定为KPI,这会自然倒逼成本、数据合规、行业化方案全面优化。
中国AI的底层优势首先是能源红利。AI是能源密集型产业。中国在这一层早就布局,十五年前就开始大规模投资输电网络和配套基础设施。中国的国家电网的年资本支出约900亿美元,而美国只有约300亿美元。中国电力装机容量是美国的2.6倍,电力产能净增量是美国的9倍。另外,新增能源部分中,太阳能和风电占主导,能够为AI提供绿色能源基础。然后是成本红利。
建设一座GW量级的数据中心,中国是4亿美元,美国则是10亿美元。这有着结构性的成本差距。
- “Chinese models are not very far behind the US, because China has a lot of engineers and it’s the country that produced the most standard students every year. […] Lacking in GPU actually creates an advantage of starvation.”
中国的AI团队在系统工程能力上已经非常突出。长期的GPU短缺,反而逼出了更高的优化效率。在分布式训练、调度优化、功耗控制等方面,中国工程师展现出较强的实践能力。而在人才供给上,“全球有超过一半的AI科学家和研究者,在中国大学有过学位。”有Meta的员工调侃:“我们的AI团队里,几乎全员讲中文。”这很有意思,“过去中文是出海的障碍,如今在AI时代,它反倒成了优势。”另外,中文互联网的内容密度、语义复杂度,也可以为AI模型提供了丰富的语料。这种语言层面的优势还在放大。
谈到AI的全球竞争格局以及中美的差异,蔡崇信重点提到开源和闭源之争。
总的来看,国家主要在两种模式种做选择:
- 一种是依赖OpenAI等公司的闭源API:性能强大;但是价格高,数据进黑箱,用户几乎无法掌握隐私和使用边界;
- 另一种是采用阿里等企业推出的开源模型:可自部署、低成本、数据可控,在安全性和灵活性上更具优势。
在美国,企业若要接入OpenAI等的服务,往往需要承担高额的订阅和调用费用,这使得AI的使用门槛居高不下。
而在中国,阿里的多个开源模型,用户已经可以自由的下载,并部署在自有的基础设施(例如自己的笔记本或者企业服务器上),成本极低。
长期来看,开源是一种更加经济、更加安全的路径,并且这也与他之前提到的普惠逻辑一致。
既然是开源模型,那公司如何赚钱?
- “We don’t make money from AI.”
阿里不是靠AI模型本身盈利,而是通过支撑AI运行的云基础设施实现商业化。阿里提供一整套底层能力,例如算力、存储、安全、数据管理、网络服务,让用户能在其云平台上稳定、高效的运行AI应用。这一完整的云产品矩阵,是AI落地的核心支撑,也逐渐形成了阿里生态的护城河。这就像酒店业,真正决定收益的,不是每个房间的装潢,而是专业化和规模化的运营效率。AI越普及,算力需求越大,云基础设施的商业价值就越高。
在个人层面,蔡崇信建议:
- “You should learn how to acquire knowledge and develop analytical framework for analyzing information coming to your conclusions.”
个人成长有两大核心能力:知识获取能力和建立分析框架的能力。
在信息爆炸时代,懂得筛选、提炼和建模,把信息处理为自己的理解系统,是真正的竞争力。
- 编程:虽然已经有vibe coding(自然语言编程),他仍然建议像学习机器逻辑,主要培养结构化思考;
- 电子表格:看似简单,是不错的逻辑推演工具;
- 数据科学:理解数字化时代的底层语言,学习检索和分析数据。
在学科方面,他建议年轻人学习心理学和生物学,去理解人脑、信息处理与决策机制;还可以关注材料科学,从比特(数字信息)到原子(物理载体),他认为下一轮技术革命将发生在物理世界,材料科学是突破一些技术瓶颈的关键领域,特别是在半导体等核心硬件领域的创新。
那么“AI会不会像互联网一样,成为泡沫?”
- “There is a real model and then there is a financial market model.”
“AI是真实存在的技术,只是金融市场会泡沫化。”
互联网当年也经历了破裂,但留下的基础设施,例如服务器、协议、带宽等等,都变成了今天的生产力。AI也是一样:它的模型、算力、基础设施,都是真实可见的资产。泡沫,是金融估值的问题,不是技术的问题。
AI能够像朋友一样给出答案、交往的时候,将是一个重要的发展节点。目前,AI更多的是一种效率工具;未来,AI有望成为人类的朋友,有更好的交互。
